


The importance of PostgreSQL timelines
Flashpoint: have you ever watched a Sci-Fi movie where the main character goes back in time, change something there (i.e. save his mother’s life) and then comes back to present days but arrives in an alternate reality? Applied to PostgreSQL backups, the alternate reality called timeline is a key notion for Point-in-Time Recovery.
Whenever an archive recovery completes, a new timeline is created to identify the series of WAL records generated after that recovery. The timeline ID number is part of WAL segment file names so a new timeline does not overwrite the WAL data generated by previous timelines. For example, in the WAL file name 0000000100001234000055CD, the leading 00000001 is the timeline ID in hexadecimal.
Let’s take an example:
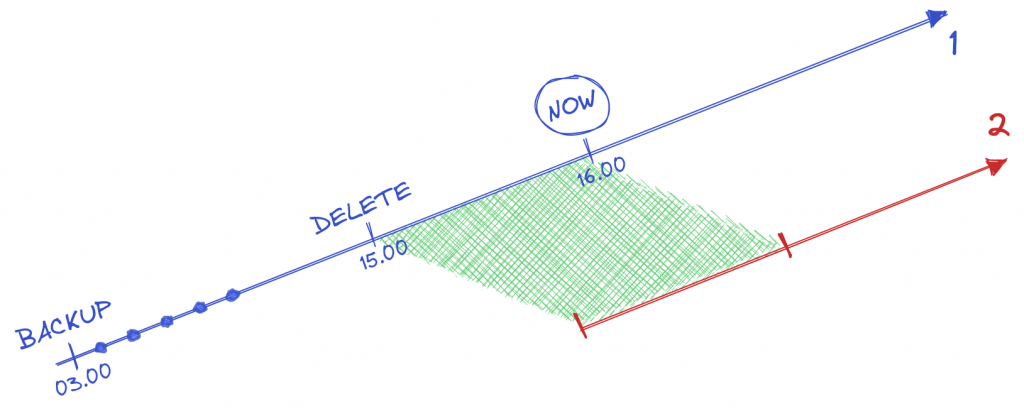
With continuous WAL archiving enabled and a backup taken at 03.00am, imagine one of your colleague coming to you at 04.00pm: «I forgot a where clause in a DELETE statement 1 hour ago and dropped some important data. Can you help me?»
Of course we can! We just have to restore the backup and ask PostgreSQL to stop its recovery before the DELETE with i.e. recovery_target_time = ‘2024-03-08 15:00:00 UTC’ (or better, use recovery_target_xid if we know the transaction id of that DELETE statement).
At the end of the recovery, the restored PostgreSQL cluster is still living in present time (> 04.00pm) but in an alternate reality, with the data that were deleted but without all the data that were added/removed/updated afterwards: timeline 2.
Now, all your other colleagues are angry because they inserted some very important data at 03.30pm and they want those data back! No problem, we still have our backup, our WAL archives and we can use recovery_target_time = ‘2024-03-08 15:30:00 UTC’ 🙂
However, if you’re running PostgreSQL 12 or later, after the recovery you won’t have the inserted data you wanted 🙁
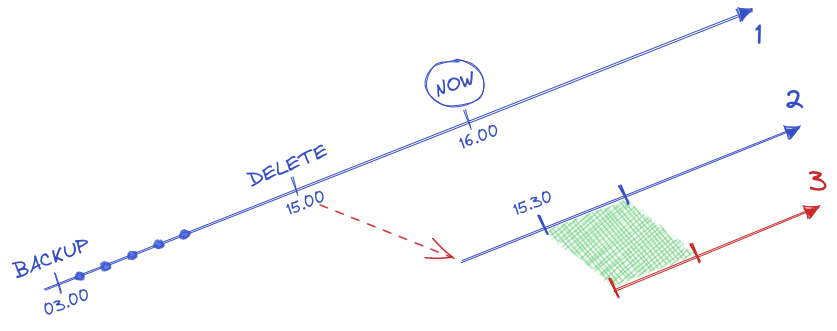
That’s because of recovery_target_timeline! By default, PostgreSQL will follow the latest timeline found. So, at 03.00pm, it will switch to timeline 2 and recover the data of this timeline until 03.30pm before creating the new timeline 3.
If you want the data from the first timeline back, you’ll need to use recovery_target_timeline = ‘0x1’ (remember, timeline IDs are hexadecimal…) or better: recovery_target_timeline = ‘current’. The current keyword will let you recover to the timeline that was current when the base backup was taken.
In fact, PostgreSQL would just ignore timeline 2 and go directly to timeline 3:
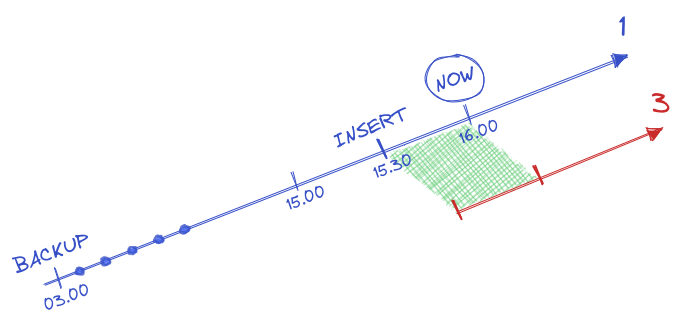
Every time a new timeline is created, PostgreSQL creates a «timeline history» file that shows which timeline it branched off from and when. These history files are necessary to allow the system to pick the right WAL segment files when recovering from an archive that contains multiple timelines. Therefore, they are archived into the WAL archive area just like WAL segment files.
To see exactly what happened, we can have a look at the history files:
$ cat 00000002.history 1 0/2E942230 before 2024-03-08 15:00:00.000334+00 $ cat 00000003.history 1 0/41D7D6B0 before 2024-03-08 15:30:00.000581+00
Learning how to perform Point-in-time recovery and understanding how to control the PostgreSQL recovery process will let you unlock a whole new world of possibilities.
Not only preventing data loss or reducing the impact of human mistakes, it can even help you rebuild a development database to the point just before a new deployment!
Uncertain that you will have a working backup should your database fail? or whether you would be able to retrieve the lost data? Not confident enough in your Disaster and Recovery practices? Then, join us for a free webinar on 18 April 13:00CET which will provide you with the methodologies and key concepts to strengthen your PostgreSQL backup strategies.




